

Khi nói đến SEO Technical, có thể khó hiểu quy trình chúnghoạt động như thế nào. Nhưng điều quan trọng là phải có được nhiều kiến thức nhất có thể để tối ưu website của mình và tiếp cận lượng người dùng lớn hơn. Một công cụ đóng một vai trò quan trọng trong việc tối ưu hóa công cụ tìm kiếm chính là Web crawler.
Trong bài đăng này, chúng ta sẽ tìm hiểu Web crawler là gì, cách chúng hoạt động và tại sao chúng nên thu thập dữ liệu web của bạn.
Web Crawler là gì?
Web crawler còn được được gọi là web spider là một bot tìm kiếm và lập chỉ mục nội dung trên internet. Về cơ bản, Web crawler có trách nhiệm hiểu nội dung trên website để có thể truy xuất nội dung đó khi có yêu cầu.
Bạn có thể tự hỏi, “Ai điều hành các Web crawler này?“
Thông thường, Web crawler được vận hành bởi các công cụ tìm kiếm với các thuật toán riêng của chúng. Thuật toán sẽ cho trình thu thập thông tin web biết cách tìm thông tin có liên quan để phản hồi một truy vấn tìm kiếm.
Một web spider sẽ tìm kiếm (crawl) và phân loại tất cả các website trên internet mà nó có thể tìm thấy và được yêu cầu lập chỉ mục. Vì vậy, bạn có thể yêu cầu web crawler không thu thập dữ liệu website của bạn nếu bạn không muốn nó được tìm thấy trên các công cụ tìm kiếm.
Để làm điều này, bạn phải tải lên tệp robots.txt. Về cơ bản, tệp robots.txt sẽ cho công cụ tìm kiếm biết cách thu thập thông tin và lập chỉ mục các trang trên website của bạn.
Ví dụ: hãy xem qua Nike.com/robots.txt.
Đối với Nike, họ đã sử dụng tệp tin robot.txt để xác định những liên kết nào trong website của mình sẽ được thu thập thông tin và lập chỉ mục.

Trong phần này của tệp, nó xác định rằng:
- Trình thu thập thông tin web Baiduspider được phép thu thập thông tin bảy liên kết đầu tiên
- Trình thu thập thông tin web Baiduspider không được phép thu thập thông tin ba liên kết còn lại
Điều này có lợi cho Nike vì một số trang mà công ty có không được sử dụng để tìm kiếm và các backlink không được phép sẽ không ảnh hưởng đến các trang được tối ưu hóa giúp họ xếp hạng trong các công cụ tìm kiếm.
Vì vậy, bây giờ chúng ta đã biết Web crawler là gì, chúng thực hiện công việc của mình như thế nào? Dưới đây, chúng ta hãy xem xét cách thức hoạt động của web crawler.
Web Crawler hoạt động như thế nào?
Web Crawler hoạt động bằng cách khám phá các URL, xem xét và phân loại các website, sau đó thêm các hyperlinks trên bất kỳ website nào vào danh sách các web cần thu thập thông tin. Web Crawler rất thông minh và có thể xác định tầm quan trọng của mỗi trang web.
Web Crawler của công cụ tìm kiếm rất có thể sẽ không thu thập thông tin toàn bộ internet. Thay vào đó, nó sẽ quyết định tầm quan trọng của mỗi trang web dựa trên các yếu tố bao gồm số lượng trang khác liên kết đến trang đó, số lượt xem trang và thậm chí cả uy tín thương hiệu.
Vì vậy, Web Crawler sẽ xác định những trang nào cần thu thập thông tin, thứ tự thu thập thông tin chúng và tần suất chúng nên thu thập thông tin để cập nhật.
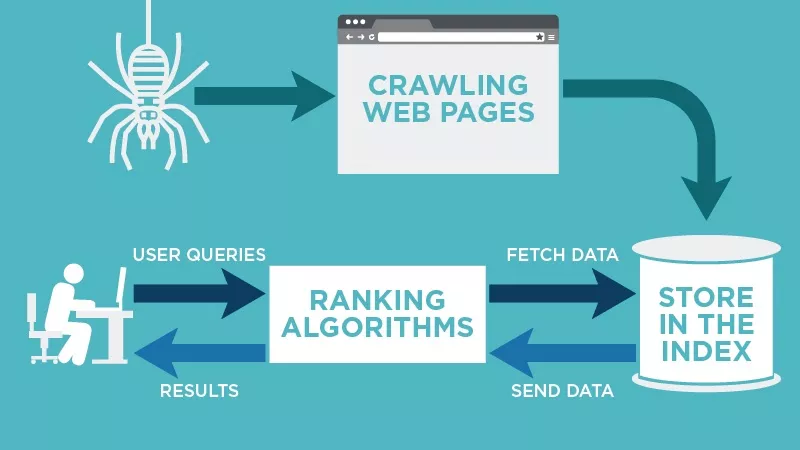
Ví dụ: nếu bạn có một website mới hoặc các thay đổi đã được thực hiện trên một trang hiện có, thì Web Crawler sẽ ghi chú và cập nhật chỉ mục. Hoặc, nếu bạn có một website mới, bạn có thể yêu cầu các công cụ tìm kiếm thu thập dữ liệu trang web của bạn.
Khi Web Crawler ở trên trang của bạn, nó sẽ xem xét nội dung và các thẻ meta, lưu trữ thông tin đó và lập chỉ mục để Google sắp xếp các từ khóa.
Trước khi toàn bộ quy trình này được bắt đầu, Web Crawler sẽ xem xét tệp robots.txt của bạn để xem những trang nào cần thu thập thông tin, đó là lý do tại sao nó rất quan trọng đối với SEO Technical.
Cuối cùng, khi Web Crawler thu thập dữ liệu trang của bạn, nó sẽ quyết định xem trang của bạn có hiển thị trên trang kết quả tìm kiếm cho một truy vấn hay không. Điều quan trọng cần lưu ý là một số Web Crawler có thể hoạt động khác với những Web Crawler khác.
Ví dụ: một số có thể sử dụng các yếu tố khác nhau khi quyết định trang web nào quan trọng nhất để thu thập thông tin.
Bây giờ chúng ta đã xem xét cách thức hoạt động của Web Crawler, chúng ta sẽ thảo luận về lý do tại sao chúng nên thu thập dữ liệu website của bạn.
Tại sao Web Crawling lại quan trọng?
Nếu bạn muốn website của mình xếp hạng trong các công cụ tìm kiếm, nó cần được lập chỉ mục. Nếu không có Web Crawler, website của bạn sẽ không được tìm thấy ngay cả khi bạn tìm kiếm trên một đoạn văn được lấy trực tiếp từ web của bạn.
Theo nghĩa đơn giản, website của bạn không tồn tại trừ khi được thu thập thông tin một lần.
Để tìm và khám phá các liên kết trên web qua các công cụ tìm kiếm, bạn phải cung cấp cho website của mình khả năng tiếp cận đối tượng mà nó muốn bằng cách thu thập thông tin – đặc biệt nếu bạn muốn tăng Organic traffic cho website của mình.
Mở rộng phạm vi tiếp cận với Web Crawling
Web Crawler chịu trách nhiệm tìm kiếm và lập chỉ mục nội dung trực tuyến cho các công cụ tìm kiếm. Chúng hoạt động bằng cách sắp xếp và lọc qua các website để các công cụ tìm kiếm hiểu nội dung của mọi trang web. Hiểu Web Crawler chỉ là một phần của SEO Technical hiệu quả có thể cải thiện đáng kể hiệu suất website của bạn.
Bài viết được tham khảo từ nguồn: blog.hubspot.com/marketing/web-crawler